Taxi¶
Overview |
Specification |
|---|---|
Observation Space |
{0, 1, …, 499} |
Action Space |
{0, 1, 2, 4, 5} |
Reward Space |
{-10, 0, 20} |
Loading String |
|
Description¶
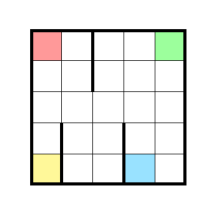
In a 5x5 grid world with four colored squares (Red, Green, Yellow, and Blue), taxi passengers spawn on one of the four squares, chosen uniformly at random. The passengers have a desired destination, also on one of the four squares chosen uniformly at random. The agent must pick up the current passenger and drop them off at their desired destination. Exactly one passenger is present on the grid at every timestep.
This environment is based on the corresponding episodic environment introduced in “Hierarchical Reinforcement Learning with the MAXQ Value Function Decomposition” by Thomas G. Dietterich. In the episodic version of Taxi, an episode terminates after a single passenger is delivered. This is a continuing version of Taxi, where a new passenger spawns once the current passenger has been successfully dropped off.
At each timestep, the taxi can move in one of the four cardinal directions, or it can attempt to perform a pick-up or drop-off on its current square. The ‘pick-up’ action is legal only when the passenger and taxi are on the same square and the passenger has not already been picked up; similarly, the ‘drop-off’ action is legal only when the passenger has been picked up and the taxi has arrived at the passenger’s destination. A passenger’s pick-up and destination location can be the same square, but the taxi must still pick up and drop off the passenger for a successful delivery.
For each passenger successfully dropped off, the agent receives a reward of +20. If the agent performs an illegal ‘pick-up’ or ‘drop-off’ action (eg. dropping off the passenger at an incorrect location), it receives a reward of -10. If a movement action causes the taxi to hit a barrier, the taxi stays in its current square.
Observations¶
The observation space is a single state index, which encodes the possible states accounting for the taxi position, location of the passenger, and four desired destination locations. Since there are 25 possible taxi positions, 5 possible locations of the passenger (either on the colored squares or in the taxi), and 4 possible destinations, there is a total of 500 discrete states.
Actions¶
There are six discrete actions.
0: Move one pixel North.
1: Move one pixel West.
2: Move one pixel South.
3: Move one pixel East.
4: Pickup the passenger.
5: Dropoff the passenger.
Rewards¶
If a passenger is in the taxi and is successfully dropped off, a reward of +20 is received.
If an illegal ‘pick-up’ or ‘drop-off’ action is performed, a reward of -10 is received.
Else the reward equals 0.
Rendering¶
Example visualizations of a few states are provided below.
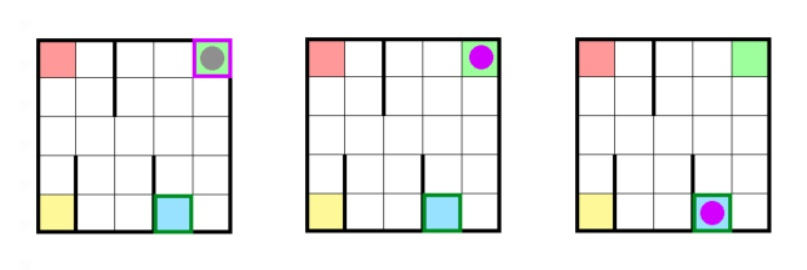
(Left) The empty taxi (grey circle) located on the same square as the passenger (purple outline), prior to pick-up.
(Middle) The taxi containing the passenger (purple circle) upon pick-up.
(Right) The taxi containing the passenger on the same square as its destination (dark green outline), prior to drop-off.